If you arrived here and you haven’t read Part 1, I would recommend it as I’ll be referencing some of the analogies and concepts introduced there in this post.
With that bit of housekeeping out of the way, lets get into it! We left off with how CXL will enable the ability for discrete computers to share peripherals and resources across the PCIe bus. This massively impacts how we think about the datapath and how we can fundamentally change the way application technologies are architected and designed. In this post we will quickly step through a little bit of that history, and then dive into how CXL delivers real enterprise value as opposed to pure technical coolness.
How We Got Here? #
Today’s Landscape - Distributed Computing Made Easy #
In the current world we have figured out all kinds of ways to make applications run at web scale TM. But what we have really done is make a lot of trade-offs in favor of accomplishing specific enterprise goals with regard to the application at hand. Distributed computing used to require things like ‘forethought’ and ‘resource planning.’ Now you can just push a few buttons in a dashboard and a kubernetes operator will spin you up an entire distributed database cluster in under 15 minutes that can handle 2008 levels of Facebook traffic like it was a joke. That didn’t come for free…
What we see now is extreme overprovisioning, tons of wasted or stranded resources, and topologies that are so complex you need to describe them as “Galaxy” or “Nebula”, because it’s a network of “distributed systems” - All to just shove a row into or pull it out of a table. I’m not diminishing the necessity of some of these architectures. However, when it comes down to what the actual enterprise value is, we have workarounds on top of workarounds. The datapath just can’t be that straight-forward and maintain things like resiliency, durability, atomicity and most importantly developer friendliness <– we will dig into this more soon.
Below are two real examples of what I’m talking about here, one from Netflix1 and another from Uber2 :


As computers (read: Servers) became VM’s, and VM’s became containers, the handwringing question of “Scale out or up” seemingly just went away, because why would you think about the size of computer you need when you can just add as many computers as you want to solve your problem by clicking a button!
Scale Out or Scale Up? #
I intentionally ordered “Scale Out” first because the nature of today’s development in the cloud has a strong bias to scaling out before scaling up. It was one of the many tools that were given to developers to control their own development cycles. Why ask for a bigger box that has some high cost associated with it (provision time/actual money/etc.) when you could just have a micro instance or container that can do it without having to ask anyone? Rinse and repeat 1000x.
The tools we gave developers while compute was increasing in performance and efficiency gave way to ‘worry about it later,’ ‘build in the complexity first before you scale,’ because rumor has it you can always just “buy a bigger box,” and ‘it’s much harder to take a single box and turn it into a distributed service’ (hint of sarcasm here, for those in the back hyperventilating just take deep breaths).
This strategy actually worked quite well for a while, especially when the web was at a growth pace unfathomable a decade prior. Developers became focused on delivering features, while functionality and scale were relegated to devops and SRE to deal with after the fact. The issue at scale then became non-uniform machine deployment. It’s simply untenable (and in no way cost effective) to buy machines of varying capability or in a grow-as-you-go in-place upgrade during a server’s useful lifespan in a datacenter.
The operational complexity of managing 100s, 1,000s and in some cases 100,000s of non-uniform machines becomes more of a cost burden than just taking trade-offs for CPU frequency or DRAM capacity per core, etc.
The truth is, during the buying cycle most companies optimize for something called BOM Cost (Bill of Materials), and in doing so, it almost always holds that buying more of the same thing is going to be the best path forward re: cost/complexity/usability.3 In companies that still have large capex cycles this likely means overbuying and supersizing versus optimization and being conservative. After all, the purchase is amortized over the life of the server right? In companies that have pushed for pure or near pure opex cycles (Read: Cloud or IaaS) this isn’t their problem and they can actually scale up as they needTM. The problem is at some point you always reach the limits of vertical scale, those increase over time, but they are real between hardware development cycles for CPU, GPU, DRAM, and Storage alike. To combat that we had a clever workaround.
Disaggregated Infrastructure #
What happens when your scale out infrastructure actually helps you scale up certain aspects of the deployment? This is in a nutshell what disaggregated infrastructure introduced, the drawback however is high adoption cost. But, it repays itself over time the more a company can leverage turning uniform machines into non-uniform scaled up machines that work better for their use-cases.
The most obvious adopters are the cloud folks who have hundreds of millions or billions of dollars to spend on proprietary or bespoke disaggregation methodologies, but this likely isn’t a feasible path forward for most other companies4. Clouds largely do not expose these disaggregation methods to the end user in their entirety, because it’s a core part of their product offering (how they make money) and allows them to sell you fractional use of various aspects of the infrastructure.
The earliest and arguably most successful enterprise example of this is storage. Fledgling deployments included products like SANs, but now we are in full blown disaggregated territory with storage offerings from the clouds and multiple vendors like Western Digital Platforms, Pure Storage, NetApp (not their SANs), HPE and others that offer multiple pathways of connectivity with fully managed upgrade and capacity addition opportunities.
We’ve seen some of this in action from other vendors as well who created proprietary solutions such as Liqid or in the HPC space where Infiniband is used quite frequently in tandem with extremely customized, non developer friendly application topologies.
TL;DR #
Centralized web 2.0 consumption of the last decade fueled unprecedented growth in the datacenter. To handle this parabolic growth, hardware buyers focused on buying homogenous servers as large as they could afford. Those buyers, often referred to as hyperscalers, then threw layers and layers of automated complexity on top of their infrastructure in an effort to squeeze as much value from their investment as possible. Great tools trickled down to the rest of the industry, but the bits that make hyperscalers truly unique remained proprietary. New techniques to scale economically also came to exist, but are still very expensive to adopt. This leads to an environment with high complexity that can quickly come off the rails and lead to developer difficulty.
Developer Friendliness + Capability = Enterprise value #
Enter CXL. We’ve discussed at it’s core that it enabled peripherals and resources to be shared across the PCIe bus. Now that we’ve talked through why distributed computing has seen a huge spike in deployment style and what disaggregated infrastructure has to offer to solve the problem of scale with regards to distributed computing we can now put all of these together and start to see something very special emerge.
What if there was a way to achieve what is only possible today via HPC frameworks5 with off the shelf commodity hardware? That is what we are staring in the face of with the introduction of CXL. A way for developers to take back some of the responsibility that was ceded6 to the infrastructure, devops, SRE teams.
When we give developers the tools they need to leverage a more efficient datapath, that is when creativity can flourish. In a world where the developer can be creative the value they can create is extremely high, because the ability to differentiate or provide core revenue driving features can be realized in ways that were previously unattainable.
Example Usecase: Fintech real time payments #
One of the standout examples of this is real time streaming analytics paired with synchronous database replication for financial transaction data pathing. In plain English: swipe card and approve or deny transaction. What really happens behind the scenes is as close to magic as we have in the modern world, but what if I told you this could be done:
- for a fraction of the cost
- with a real world speedup that would be detectable by the final end users (Humans)
- and with expanded capabilities to allow for more of these types of transactions on the same footprint deployed today?
That is what CXL can offer.
forewarning: some drastic technical oversimplification ahead for the non-technical
Currently real time payments rely on a transaction to
- go through a load balancer
- to enter a queue
- to be processed against a security model
- then sent to a database to process the commit in 2 or more phases
- to then persist the data on at least 2 different nodes with guarantees for consistency
with all the latency required for the back and forth communication between all of these processes happening over ethernet, wherein each hop with modern equipment and best practices adds 1-100ms. There are more than 100 places the data needs to go before it finally is at rest and the transaction is settled. Not only does this data need to be transported via some network, but it also needs to be replicated and copied multiple times so each individual application space can do any transformation, processing or storage.
When you have 20 containers in a distributed system passing the same data between all of the nodes, and a consensus protocol that verifies all of that data over the network, you can see how even though this happens in a fraction of a second today it is incredibly inefficient use of actual physical resource, but also on top of that each of these individual applications and their runtimes add to the complexity of the system to the point of “galaxy” type descriptions.
Using the CXL 3.1 specification that same datapath can be drastically simplified, and applications can be architected to leverage the data simultaneous and synchronously because the data doesn’t need to move to allow for processing. We can have a single data pipeline, load balanced appropriately, and replicated at the memory level across failure domains within a shared memory pool. So, the same data goes the 2 different places at the same time, but once it arrives all the processing can be done in-place and all transformations of that data can instantaneously be read or notify other parts of the application infrastructure of their state with drastically less consensus communication than is done today.
CXL 3.1 fabrics enable cycles and semaphores measured in nano- as opposed to (potentially hundreds of) milliseconds, and allows for simultaneous transformations to occur on the same base data in memory. The order of operations can be synchronous, with the final transaction approval being done in near real time if the transaction is ready to commit before the fraud analytics are done or immediately after if there is no need to “check” or “poll”, it will all just be available in real time to the application when it accesses the shared memory space. All of this happens and can save:
- 2-4x the persistent storage
- 5-10x the DRAM
- 100-1000x the latency
and have a higher affinity to providing additional valuable services to the end user in the same period of time the end customer is accustomed to7.
Check out a publicly available example of how netflix does real time pipelining right now8. Notice how much the data has to move. What if each of these services could just leverage it as local shared memory. I think this helps snap into focus the shortcut to what is possible.
Likewise we can see the graphQL implementation9 addresses some major concerns especially with querying data, but the data path is now reliant on a series of eventually consistent microservices behind a federated gateway. In an oversimplified example imagine if the monolithic data store (a single addressable far memory pool with RAIM and replication build in) could be leveraged as opposed to sending the data to multiple microservices to process out of an already distributed database with eventual consistency and replication.
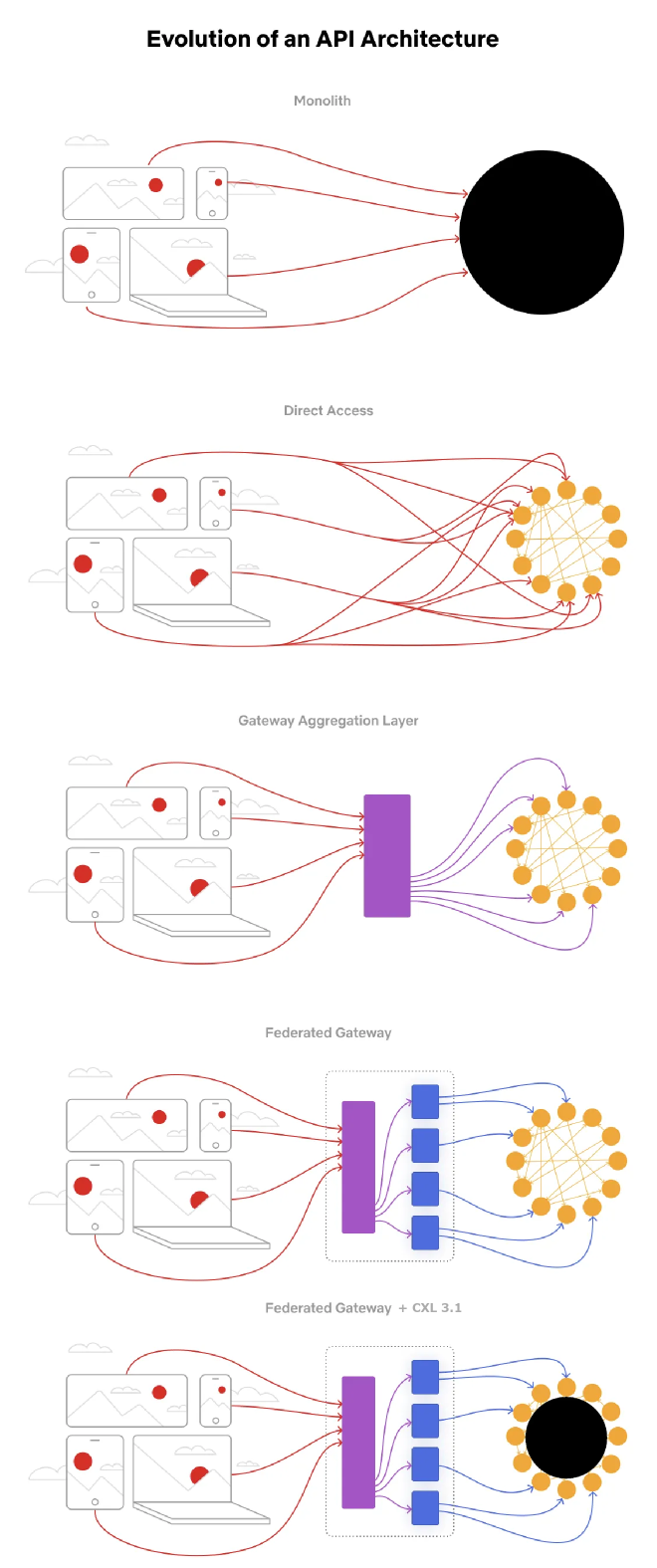
How Can CXL Benefit Your Company? #
If you find yourself asking this question at the end of this blog and you aren’t a fintech company processing payments, the team at Jackrabbit Labs would love to help. Our company’s mission is to help everyone realize and unlock their potential enterprise value using CXL. We offer a range of consulting services that include Architecture and Design sessions to full blown Use-Case analysis to help formulate a strategy for CXL deployment in your current workflows when the hardware becomes available.
-
https://medium.com/refraction-tech-everything/how-netflix-works-the-hugely-simplified-complex-stuff-that-happens-every-time-you-hit-play-3a40c9be254b ↩︎
-
You often lose significant amounts of money, time, availability if something as simple as 256GB of memory across 16 DIMMs vs 8 DIMMs is a choice you make incorrectly. ↩︎
-
There has been some recent expansion in the space due to commoditization of some of the technology, but it is still largely out if reach for most without serious capex budgets. ↩︎
-
which to put simply, actually require something close to a PhD in Computer Science to be able to build anything useful out of ↩︎
-
or jettisoned depending on your personal viewpoint ↩︎
-
There is also a drastic amount of compute cycles that would have otherwise been waiting that can now be leveraged to process even more data and transactions. ↩︎
-
https://netflixtechblog.com/nts-real-time-streaming-for-test-automation-7cb000e933a1 ↩︎
-
https://netflixtechblog.com/how-netflix-scales-its-api-with-graphql-federation-part-1-ae3557c187e2 ↩︎